Avoiding Data Leakage in Machine Learning
To properly evaluate a machine learning model, the available data must be split into training and test subsets. Data leakage occurs when, in one way or another, information regarding the test set inappropriately influences the training or evaluation of the model. This causes us to overestimated the performance of a model. We will detail a number of ways in which models can fall victim to data leakage, and offer solutions to both engineers and business owners on how to avoid them.
Failing to Split
The most obvious way this can happen is if no train-test split is made at all. In this case, the predictive skill of the model is evaluated solely on the training data. This leads to overfitting and poor generalizability to new data. Engineers that neglect to split up their data are typically overconfident in the accuracy of their predictions.
- Engineers: Always split your data. Try more complex methods like cross-validation or walk-forward optimization if your data is suited to it.
- Business Owners: It is always reasonable to require your engineers to split the data somehow. The way it is split may be complex and application-specific, but it should always be split, nonetheless.
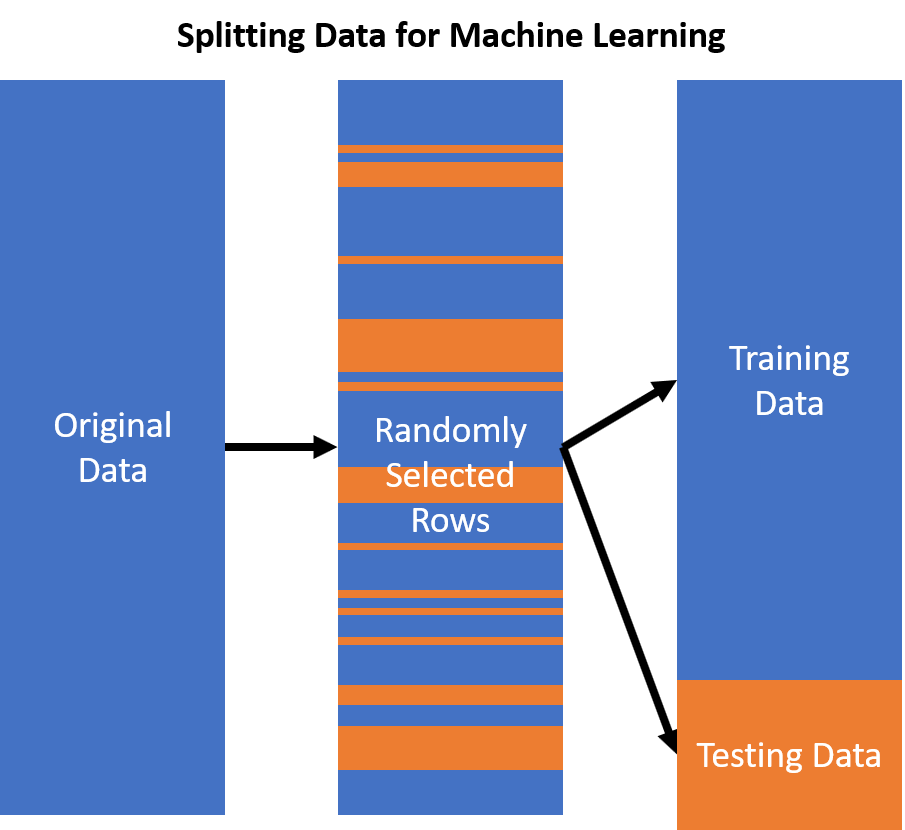
This issue is usually caused by lack of experience on part of the engineer. We will move on to discuss less obvious ways data leakage can occur.
Tuning Hyperparameters
Hyperparameters are values passed to the machine learning model that answer questions such as...
- Where will it look?
- How fast will it adjust to new information?
- Under what criteria will it converge/fail?
If the engineer tunes these hyperparameters to optimize performance on the split data, it inadvertently introduces information about the test data into the model. This defeats the original purpose of the train-test split, which is to keep the test data free from outside influence. In certain models, this can be a serious problem that renders the work-product useless on real-world data.
We can prevent this by splitting the data three ways into training, testing, and validation. Under this schema, the engineer is permitted to tune hyperparameters according to out-of-sample performance. This is not always the best splitting schema, but it is certainly required where the engineer is tuning hyperparameters.
- Engineers: Well-conditioned models like multiple regression rarely require tuning of hyperparameters, so there is no need for a 3-way split. If you tune hyperparameters, which are common for neural networks and decision trees, use 3-way splits to guard your work from data leakage.
- Business Owners: Data leakage is a complex and non-trivial problem. To assure you are getting accurate measurements of performance, consider holding back some of the data from the engineers altogether. Testing on this data will give you an unbiased perspective on the value of the model.
Normalization
Many models require normalization of the input data, especially neural networks. Commonly, data is normalized by dividing it by its average or maximum. If this is done using the average or maximum of the overall data set, then information from the test set will now be influencing the training set. For this reason, any normalization should be applied on a subset basis.
- Engineers: Besides following the above guidelines, make sure to only normalize data when absolutely necessary. This will help you avoid accidental pitfalls.
Special Case: Time Series
Data leakage can be especially tricky with time series. Not only do we have to worry about the pitfalls above, we also need to make sure we are not leaking information from the future into the past. When dealing with time series, it would be a mistake to randomly split the data into train and test sets. That would lead to, for example, making predictions about 2016 using data from 2017.

The data from 2017 was obviously not available in 2016. When the final model is deployed, no data from the subsequent year will be available. Like other forms of data leakage, predicting the past with the future will cause us to overestimate the performance of the model. In time series, we use walk-forward optimization to dynamically (and chronologically) split training and test data. Walk-forward optimization mimics the appearance of training your model once each year for use in the following year, which is a realistic application.
Featurization using Target Values
The data preparation and cleaning process is often very long and disjoint from the machine learning process. Machine learning engineers often joke about their jobs are 90% data cleaning and 10% machine learning... because this is mostly true. The point is: It is easy for data from the target values to accidentally influence the predictors. When this happens, we end up running models that make unrealistically good predictions. An experienced engineer will be weary of overly accurate results for this reason.
Exceedingly good results usually indicate featurization errors.
Example in Financial Trading
In financial trading, there are ample opportunities for this type of leakage. Often, the researcher will use technical indicators such as moving averages as features. Say we are training a model to predict the closing price of a stock one day ahead using the previous 2 years of price data. We will train our model using various moving averages and other indicators as features.
We could, for example, train it on data from the first year and evaluate it on data from the second year. However, splitting the data this way is not enough. Some of our features are calculated from, and hence include information about, the price we are trying to predict. To deal with this, we need to lag the indicators at least one day behind the price.
Example in Medical Research
Featurization using target values may also occur in non-time-series data. For example, a medical researcher may be trying to predict whether someone has a disease. To do so, they train a model on a variety of features such as family history, demographics, diet, and medical records. Without proper care, information regarding treatment for the disease may leak into the features.
Obviously, whether a person was treated will be highly predictive of whether they had the disease. It may almost seem ludicrous that such a simple mistake could be made, but it does happen, especially in the case of large data sets with many features. In fact, a recent Kaggle competition reported this exact scenario occurred in a prostate cancer data set.
Conclusion
- Business Owners: Don't be afraid to hold your engineers accountable for performance on out-of-sample data. Out-of-sample performance is ultimately what determines the value of a model. Hold back some of your own data from engineers and be the impartial adjudicator on the performance of the model.
- Engineers: If your model is performing too well, reflect on your methods before popping open the champagne. It is most likely that some form of data leakage is occurring. Make sure you understand your data, rather than view it as a homogeneous pile of numbers. Some features may be ex-ante indicators of a target, and should be excluded altogether.